K08 - edge retention (1/8", ridged cardboard)
Posted: Thu Nov 29, 2012 4:18 pm
This isn't going to be overly exciting unless you are interested in the real fundamentals of edge retention and especially the influence of random variation and how to deal with it.
Here is the first run which is used on really non-abrasive cardboard to give a high end benchmark :
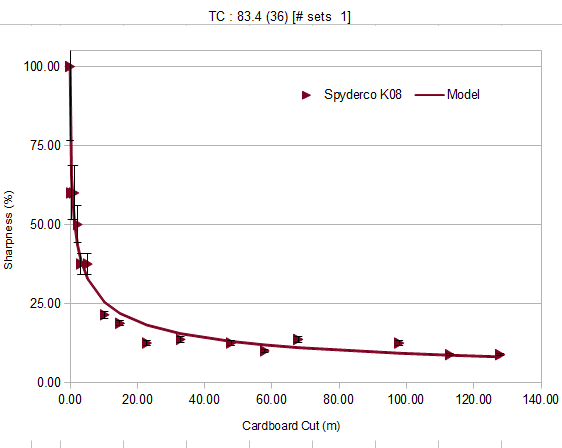
Note the obvious features :
-high scatter
-very high initial loss
-long and very stable plateau starts to set in when sharpness is about 25%
-very high total cut count, but very large uncertainty
Second run :
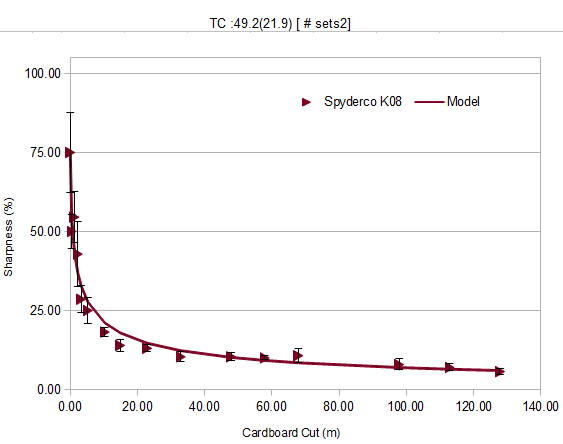
This and all subsequent runs are done with random sampling on the cardboard. Note :
-same shape (all blunting has to have this curve)
-reduction in total cut count and uncertainty
-data starting to fit the curve much better
Third :
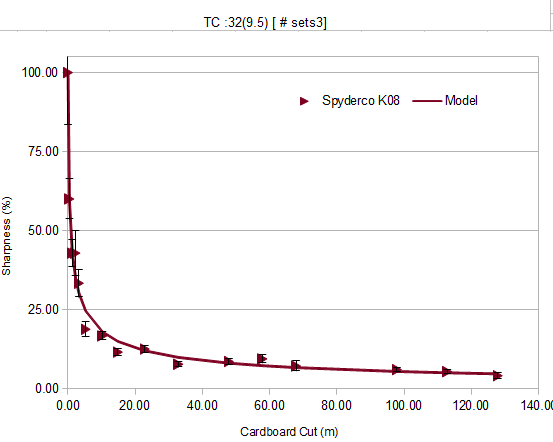
Similar changes.
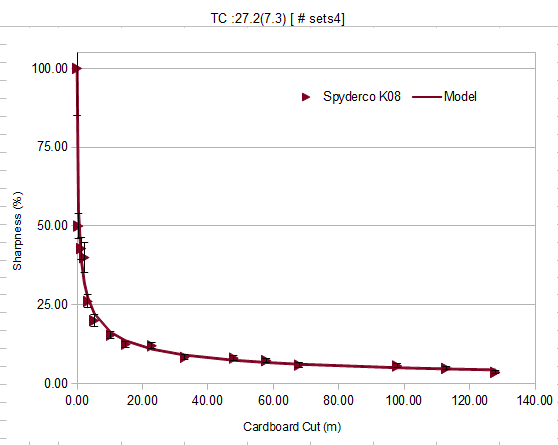
Again, note how the changes keep decreasing as the data becomes stable.
Fifth run :
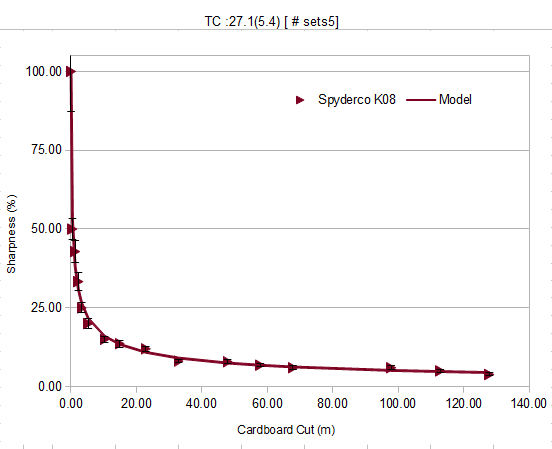
Almost no change now, the data is decently stable.
An over view :
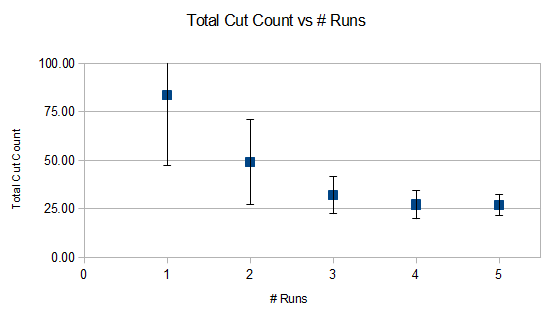
Among other things this illustrates how multiple runs are needed to get a decent performance estimate and how even just a couple of extra runs will achieve this easily. Note median statistics were used in the above as they are inherently better able to handle large deviations.
Here is the first run which is used on really non-abrasive cardboard to give a high end benchmark :
Note the obvious features :
-high scatter
-very high initial loss
-long and very stable plateau starts to set in when sharpness is about 25%
-very high total cut count, but very large uncertainty
Second run :
This and all subsequent runs are done with random sampling on the cardboard. Note :
-same shape (all blunting has to have this curve)
-reduction in total cut count and uncertainty
-data starting to fit the curve much better
Third :
Similar changes.
Again, note how the changes keep decreasing as the data becomes stable.
Fifth run :
Almost no change now, the data is decently stable.
An over view :
Among other things this illustrates how multiple runs are needed to get a decent performance estimate and how even just a couple of extra runs will achieve this easily. Note median statistics were used in the above as they are inherently better able to handle large deviations.